

Flow: How To Run Flow on A Huge Amount of Data
In one of the conversations with Alex, the founder of the cool YouTube channel FlowFanatic, he reminded me that Flow is still not the best tool when dealing with a big amount of data as the limit of executed elements is 2000. I even wrote this in the Governor Limits article, but I didn’t think that far about how it puts a limit on the data size. However, I wonder if it is really impossible for Flow to handle many records due to this element limit. Thus in this article, I am testing how each type of Flows handles huge sizes of data.
Testing Goal
In this General Flow Limit article, it says the limit of Executed elements at runtime per flow is 2000. I don’t find this definition really accurate. What does “per flow” mean? Is it per transaction or something else? Thus this is what we want to find out at the end of this experiment. I will use Account and Contact objects for the testing.
How to Calculate Executed Elements
First to recap on how the executed elements are calculated. Based on the official article, the elements outside the loop will count as 1, and the elements inside the loop (including the loop itself) will count as 1 * [Number of Records]. For example, if you have 10 records with 2 outer elements and 3 inner elements, the total executed elements are 2 + 3 * 10 = 32.
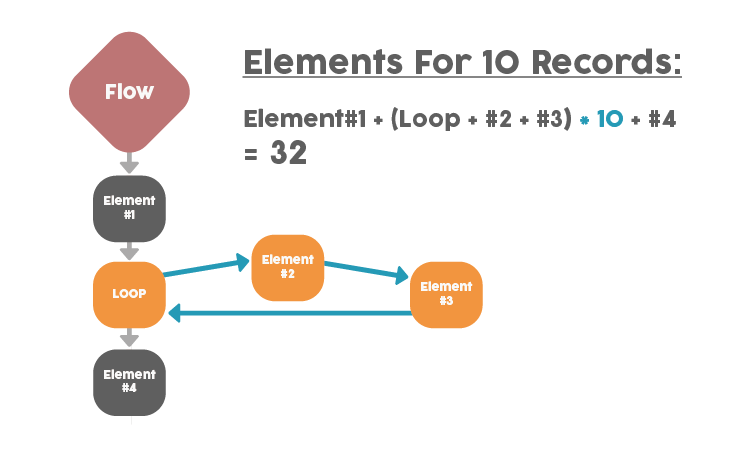
Autolaunched Flow
Scenario 1:
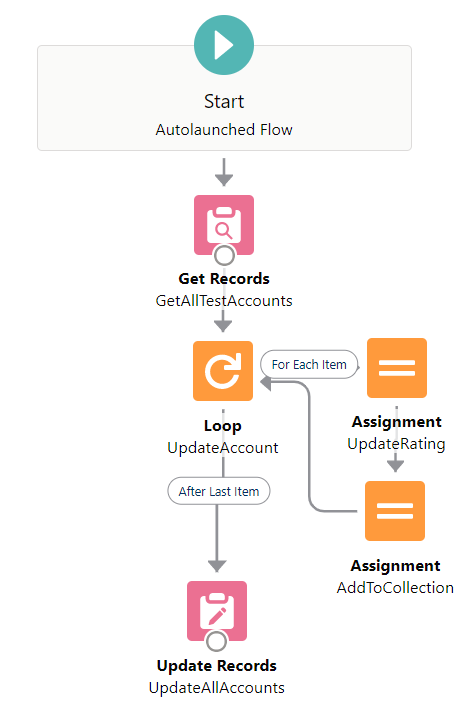
1000 Accounts on 2 outer + 3 inner elements
This flow interview will have 2 + 3 * 1000 = 3002 elements. I hit an iteration limit error as expected.
Result: Failed
Screen Flow
Scenario 1:
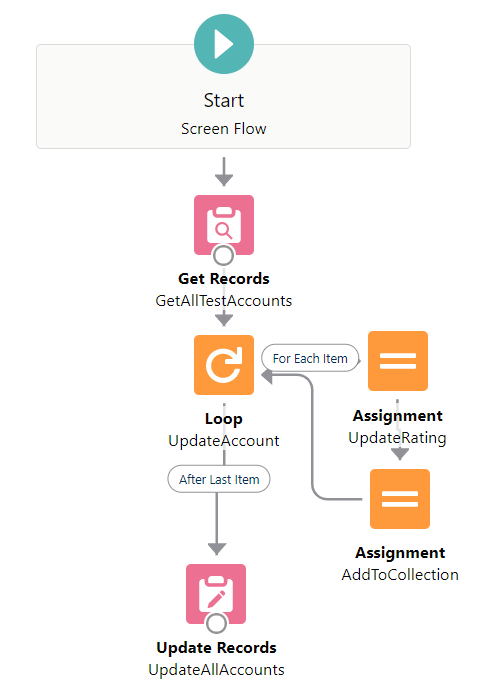
1000 Accounts on 2 outer + 3 inner elements
This scenario is basically the same as the autolaunched flow, so I also hit an iteration limit error.
Result: Failed
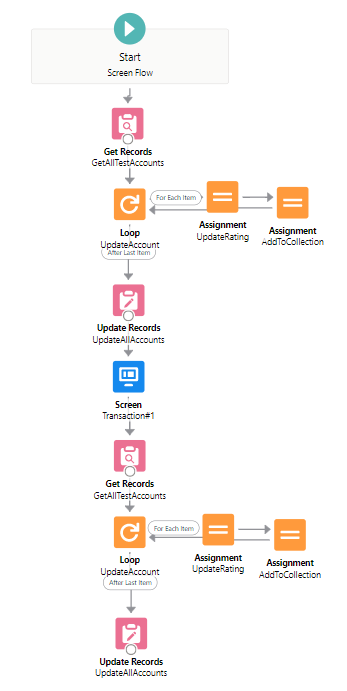
Scenario 2:
500 Accounts on 2 outer + 3 inner elements + Screen +
500 Accounts on 2 outer + 3 inner elements
Then I was thinking, since a Screen element can generate a new transaction, would it also reset the element limit? Thus I divided the flow into two transactions by a screen element, and run 500 accounts in each (2 + 3 * 500 = 1502 elements in each transaction. 3004 elements in total).
Turned out it works! Here we can safely conclude the element limit is reset by a new transaction.
Result: Succeed
Record- or Schedule-Triggered Flow
I tested these two types separately and realized the results are the same, so I summarize them together.
Scenario 1:
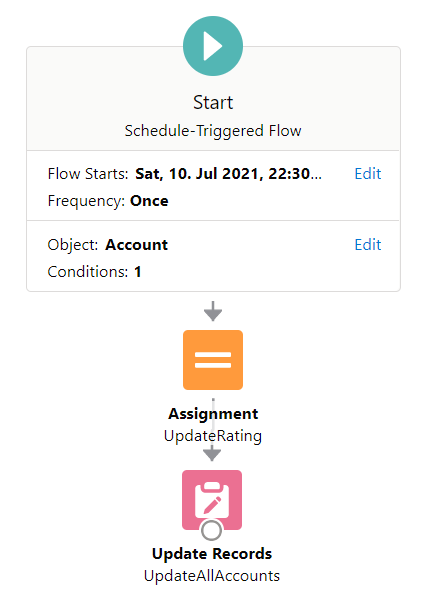
1050 Accounts on 2 elements
The Record- and Schedule-Triggered flow support bulkification, which means we can build the flow as if it is for only one record, and it will automatically loop through all records. So I tested 1050 Accounts on 2 elements, thinking the total elements will be 2 * 1050 = 2100.
For Schedule-Triggered flow, several transactions will be generated with a batch size of 200, so this test passed without problem as we knew from the previous test indicates a transaction will reset the limit.
But then a cool thing happened! I realized for Record-Triggered flow, even though there is only one transaction, one record will create one flow interview, and all the interviews will be batched with a size of 200. This also passed the test, so we know a batch of interviews also resets the limit.
Result: Succeed
Scenario 2:
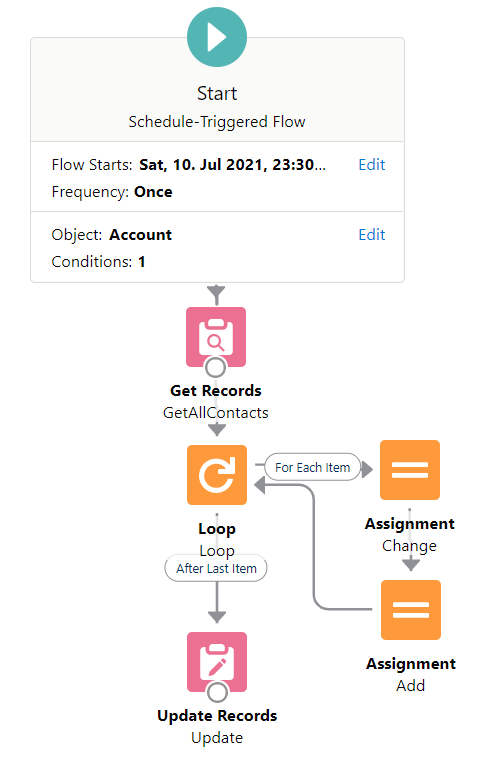
200 Accounts with 10 Contacts each on 2 outer + 3 inner elements
Ok, since the system only runs for 200 records at a time, what if I add 10 contacts to each Account, and loop through all contacts? My thought is that for each Account, there will be 2 + 3 * 10 = 32 elements, so for 200 accounts, there will be 32 * 200 = 6400 elements.
SURPRISINGLY IT STILL WORKS! So not only a transaction and a batch of flow interviews will rest the element limit, but each record (interview) will also reset the limit.
Result: Succeed
Scenario 3:
1 Accounts with 1000 Contacts on 2 outer + 3 inner elements
To confirm the result, the last scenario is to run only one Account but loop through 1000 related contacts. I hit the iteration error again, so now we know the 2000 elements limit is for each record in a Record- or Schedule-Triggered flow.
Result: Failed
SUMMARY
Conclusion
The element limit of 2000 is for each flow interview in a transaction. In Screen flows, we can use a Screen element to start a new transaction.
Takeaway
If we want to run flows on a huge amount of data, utilize schedule- or record-triggered flow for the bulkification feature. But note that record-triggered flow still only generate one transaction, so pay attention to other governor limits.
Lastly, Apex can still handle this situation better at the moment. To handle mass data, leverage the power of Apex codes or upvote this idea of increasing the limit.
This is excellent research. Thanks so much for doing it and I really wish Alex & the team would document this limit in more detail. I have avoided scheduled flows (and *cringe* built scheduled Apex) to work on 3000 contacts I have. Now I know better!
Thanks Charles, glad that it helped! Yes I really hope these details can be documented somewhere, so we know better on how to choose between flow and apex.
You set up a beautiful experiment, and the data is highly rewarding. Excellent, Melody!
Just to understand more clearly, if there is DML update of 10k records(which is max) of same object and having a record-triggered flow on the same particular object can create 50 flow interviews(10000/200 bcz of SF default batch size) and each flow interview comes with a 2000 element limit ?
This is one the most helpful posts I have ever read! One thing that confused me: “The Record- and Schedule-Triggered flow support bulkification, which means we can build the flow as if it is for only one record, and it will automatically loop through all records.” That sounds great because I want a flow to loop through all records of a custom object to add ContentDocumentLinks. But how do you get it to automatically loop through all records? In a record triggered flow doesn’t it only trigger when a record is created or updated? My aha moment was creating a record-trigger flow, and then creating a one-step schedule-triggered flow (specify conditions to identify records, and set fields individually, with no filter) that simply updates all records, hence triggering my record-triggered flow for each individual record. However that yielded a series of errors: “Heap limit (500K records) exceeded: 862600 total records accessed across 200 interviews.” Since I only have around 10,000 records, it seems the two flows I created must have created some sort of infinite loop. What is the correct way to get a flow to run on each record with bulkification?
Does this only work with ‘update’ and not ‘create’? I have a screen flow (that must stay a screen flow because it’s manually run by a user at random times) that creates records, wouldn’t the 2nd transaction just attempt duplicate what was already created in the first transaction? Or does the flow have an internal “breakpoint” at which it’ll automatically move to the Transaction screen and into the 2nd Transaction?